Simon Josefsson: Privilege separation of GSS-API credentials for Apache
To protect web resources with Kerberos you may use Apache HTTPD with mod_auth_gssapi however, all web scripts (e.g., PHP) run under Apache will have access to the Kerberos long-term symmetric secret credential (keytab). If someone can get it, they can impersonate your server, which is bad.
The gssproxy project makes it possible to introduce privilege separation to reduce the attack surface. There is a tutorial for RPM-based distributions (Fedora, RHEL, AlmaLinux, etc), but I wanted to get this to work on a DPKG-based distribution (Debian, Ubuntu, Trisquel, PureOS, etc) and found it worthwhile to document the process. I m using Ubuntu 22.04 below, but have tested it on Debian 11 as well. I have adopted the gssproxy package in Debian, and testing this setup is part of the scripted autopkgtest/debci regression testing.
First install the required packages:
Then configure gssproxy to find the credential and use it with Apache.
When systemd is used the following can be used to set the environment variable, note the final command to reload systemd.
root@foo:~# apt-get update
root@foo:~# apt-get install -y apache2 libapache2-mod-auth-gssapi gssproxy curlfoo.sjd.se in this writeup.
root@foo:~# curl --head http://foo.sjd.se/
HTTP/1.1 200 OK
kadmin ktadd or ipa-getkeytab), but use the string HTTP/foo.sjd.se and then confirm using something like the following.root@foo:~# ls -la /etc/gssproxy/httpd.keytab
-rw------- 1 root root 176 Sep 18 06:44 /etc/gssproxy/httpd.keytab
root@foo:~# klist -k /etc/gssproxy/httpd.keytab -e
Keytab name: FILE:/etc/gssproxy/httpd.keytab
KVNO Principal
---- --------------------------------------------------------------------------
2 HTTP/foo.sjd.se@GSSPROXY.EXAMPLE.ORG (aes256-cts-hmac-sha1-96)
2 HTTP/foo.sjd.se@GSSPROXY.EXAMPLE.ORG (aes128-cts-hmac-sha1-96)
root@foo:~# /etc/krb5.keytab location, so Apache s libapache2-mod-auth-gssapi will have to use gssproxy to use it.Then configure gssproxy to find the credential and use it with Apache.
root@foo:~# cat<<EOF > /etc/gssproxy/80-httpd.conf
[service/HTTP]
mechs = krb5
cred_store = keytab:/etc/gssproxy/httpd.keytab
cred_store = ccache:/var/lib/gssproxy/clients/krb5cc_%U
euid = www-data
process = /usr/sbin/apache2
EOFgssproxy logging:
root@foo:~# cat<<EOF > /etc/gssproxy/gssproxy.conf
[gssproxy]
debug_level = 1
EOF
root@foo:~#root@foo:~# tail -F /var/log/syslog &
root@foo:~# systemctl restart gssproxySep 18 07:03:15 foo gssproxy[4076]: [2022/09/18 05:03:15]: Exiting after receiving a signalThe NFS-related errors is due to a default gssproxy configuration file, it is harmless and if you don t use NFS with GSS-API you can silence it like this:
Sep 18 07:03:15 foo systemd[1]: Stopping GSSAPI Proxy Daemon
Sep 18 07:03:15 foo systemd[1]: gssproxy.service: Deactivated successfully.
Sep 18 07:03:15 foo systemd[1]: Stopped GSSAPI Proxy Daemon.
Sep 18 07:03:15 foo gssproxy[4092]: [2022/09/18 05:03:15]: Debug Enabled (level: 1)
Sep 18 07:03:15 foo systemd[1]: Starting GSSAPI Proxy Daemon
Sep 18 07:03:15 foo gssproxy[4093]: [2022/09/18 05:03:15]: Kernel doesn't support GSS-Proxy (can't open /proc/net/rpc/use-gss-proxy: 2 (No such file or directory))
Sep 18 07:03:15 foo gssproxy[4093]: [2022/09/18 05:03:15]: Problem with kernel communication! NFS server will not work
Sep 18 07:03:15 foo systemd[1]: Started GSSAPI Proxy Daemon.
Sep 18 07:03:15 foo gssproxy[4093]: [2022/09/18 05:03:15]: Initialization complete.
root@foo:~# rm /etc/gssproxy/24-nfs-server.conf
root@foo:~# systemctl try-reload-or-restart gssproxySep 18 07:18:59 foo systemd[1]: Reloading GSSAPI Proxy DaemonTo instruct Apache or actually, the MIT Kerberos V5 GSS-API library used by mod_auth_gssap loaded by Apache to use gssproxy instead of using
Sep 18 07:18:59 foo gssproxy[4182]: [2022/09/18 05:18:59]: Received SIGHUP; re-reading config.
Sep 18 07:18:59 foo gssproxy[4182]: [2022/09/18 05:18:59]: Service: HTTP, Keytab: /etc/gssproxy/httpd.keytab, Enctype: 18
Sep 18 07:18:59 foo gssproxy[4182]: [2022/09/18 05:18:59]: New config loaded successfully.
Sep 18 07:18:59 foo systemd[1]: Reloaded GSSAPI Proxy Daemon.
/etc/krb5.keytab as usual, Apache needs to be started in an environment that has GSS_USE_PROXY=1 set. The background is covered by the gssproxy-mech(8) man page and explained by the gssproxy README.When systemd is used the following can be used to set the environment variable, note the final command to reload systemd.
root@foo:~# mkdir -p /etc/systemd/system/apache2.service.d
root@foo:~# cat<<EOF > /etc/systemd/system/apache2.service.d/gssproxy.conf
[Service]
Environment=GSS_USE_PROXY=1
EOF
root@foo:~# systemctl daemon-reloadroot@foo:~# cat<<EOF > /etc/apache2/conf-available/private.conf
<Location /private>
AuthType GSSAPI
AuthName "GSSAPI Login"
Require valid-user
</Location>GSS_USE_PROXY variable. This just applies to the first time, after the first restart you may use reload again.
root@foo:~# a2enconf privateWhen you have debug messages enabled, the log may look like this:
Enabling conf private.
To activate the new configuration, you need to run:
systemctl reload apache2
root@foo:~# systemctl restart apache2
Sep 18 07:32:23 foo systemd[1]: Stopping The Apache HTTP ServerFinally, set up a dummy test page on the server:
Sep 18 07:32:23 foo gssproxy[4182]: [2022/09/18 05:32:23]: Client [2022/09/18 05:32:23]: (/usr/sbin/apache2) [2022/09/18 05:32:23]: connected (fd = 10)[2022/09/18 05:32:23]: (pid = 4651) (uid = 0) (gid = 0)[2022/09/18 05:32:23]:
Sep 18 07:32:23 foo gssproxy[4182]: message repeated 4 times: [ [2022/09/18 05:32:23]: Client [2022/09/18 05:32:23]: (/usr/sbin/apache2) [2022/09/18 05:32:23]: connected (fd = 10)[2022/09/18 05:32:23]: (pid = 4651) (uid = 0) (gid = 0)[2022/09/18 05:32:23]:]
Sep 18 07:32:23 foo systemd[1]: apache2.service: Deactivated successfully.
Sep 18 07:32:23 foo systemd[1]: Stopped The Apache HTTP Server.
Sep 18 07:32:23 foo systemd[1]: Starting The Apache HTTP Server
Sep 18 07:32:23 foo gssproxy[4182]: [2022/09/18 05:32:23]: Client [2022/09/18 05:32:23]: (/usr/sbin/apache2) [2022/09/18 05:32:23]: connected (fd = 10)[2022/09/18 05:32:23]: (pid = 4657) (uid = 0) (gid = 0)[2022/09/18 05:32:23]:
root@foo:~# Sep 18 07:32:23 foo gssproxy[4182]: message repeated 8 times: [ [2022/09/18 05:32:23]: Client [2022/09/18 05:32:23]: (/usr/sbin/apache2) [2022/09/18 05:32:23]: connected (fd = 10)[2022/09/18 05:32:23]: (pid = 4657) (uid = 0) (gid = 0)[2022/09/18 05:32:23]:]
Sep 18 07:32:23 foo systemd[1]: Started The Apache HTTP Server.
root@foo:~# echo OK > /var/www/html/private"--negotiate" enables SPNEGO and "--user :" asks curl to use username from the environment.
root@foo:~# klist
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: jas@GSSPROXY.EXAMPLE.ORG
Valid starting Expires Service principal
09/18/22 07:40:37 09/19/22 07:40:37 krbtgt/GSSPROXY.EXAMPLE.ORG@GSSPROXY.EXAMPLE.ORG
root@foo:~# curl --negotiate --user : http://foo.sjd.se/private
OK
root@foo:~#Sep 18 07:56:00 foo gssproxy[4872]: [2022/09/18 05:56:00]: Client [2022/09/18 05:56:00]: (/usr/sbin/apache2) [2022/09/18 05:56:00]: connected (fd = 10)[2022/09/18 05:56:00]: (pid = 5042) (uid = 33) (gid = 33)[2022/09/18 05:56:00]:The Apache log will look like this, notice the authenticated username shown.
Sep 18 07:56:00 foo gssproxy[4872]: [CID 10][2022/09/18 05:56:00]: gp_rpc_execute: executing 6 (GSSX_ACQUIRE_CRED) for service "HTTP", euid: 33,socket: (null)
Sep 18 07:56:00 foo gssproxy[4872]: [CID 10][2022/09/18 05:56:00]: gp_rpc_execute: executing 6 (GSSX_ACQUIRE_CRED) for service "HTTP", euid: 33,socket: (null)
Sep 18 07:56:00 foo gssproxy[4872]: [CID 10][2022/09/18 05:56:00]: gp_rpc_execute: executing 1 (GSSX_INDICATE_MECHS) for service "HTTP", euid: 33,socket: (null)
Sep 18 07:56:00 foo gssproxy[4872]: [CID 10][2022/09/18 05:56:00]: gp_rpc_execute: executing 6 (GSSX_ACQUIRE_CRED) for service "HTTP", euid: 33,socket: (null)
Sep 18 07:56:00 foo gssproxy[4872]: [CID 10][2022/09/18 05:56:00]: gp_rpc_execute: executing 9 (GSSX_ACCEPT_SEC_CONTEXT) for service "HTTP", euid: 33,socket: (null)
127.0.0.1 - jas@GSSPROXY.EXAMPLE.ORG [18/Sep/2022:07:56:00 +0200] "GET /private HTTP/1.1" 200 481 "-" "curl/7.81.0"Congratulations, and happy hacking!
 Introduction: an immutable OS
The
Introduction: an immutable OS
The 
 Since a long time ago I ve been a
Since a long time ago I ve been a
 As part of the continuing work to
As part of the continuing work to 

 A short while after
A short while after  Almost a year ago I added a script made by
Almost a year ago I added a script made by 
 The fourteenth release of
The fourteenth release of 

 Prerequisites
You will need the following prerequisites :
Prerequisites
You will need the following prerequisites :
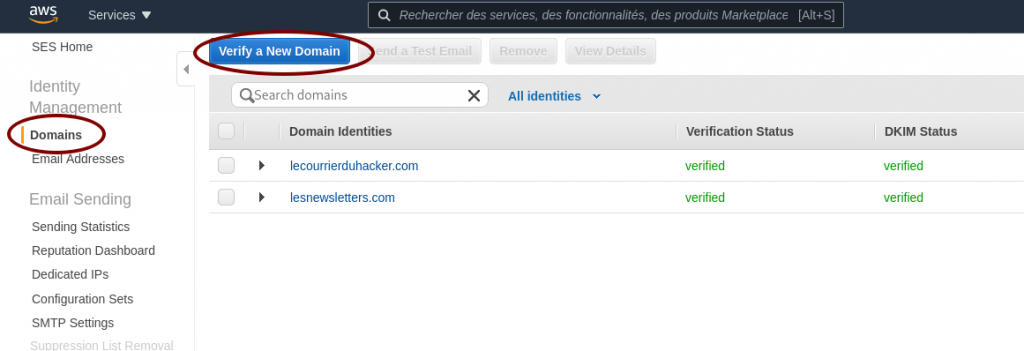 Ask AWS SES to verify a domain
Ask AWS SES to verify a domain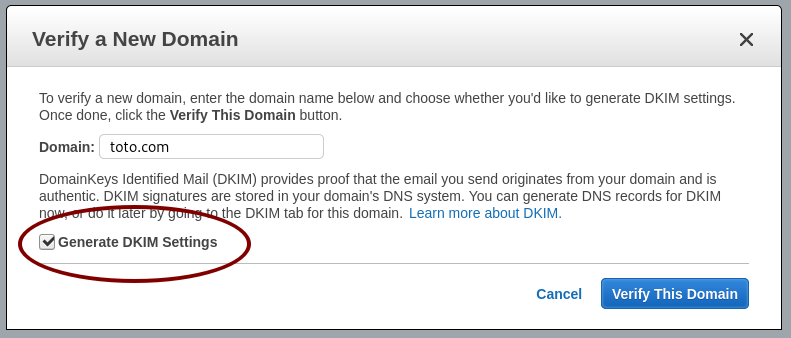 Generate the DKIM settings
Generate the DKIM settings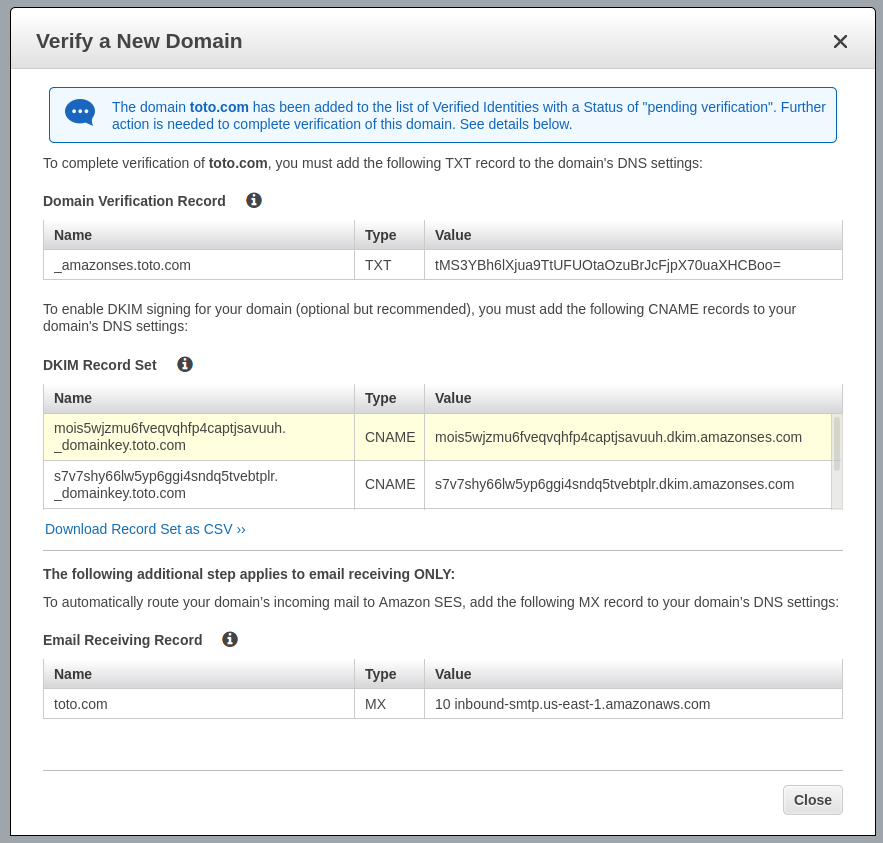
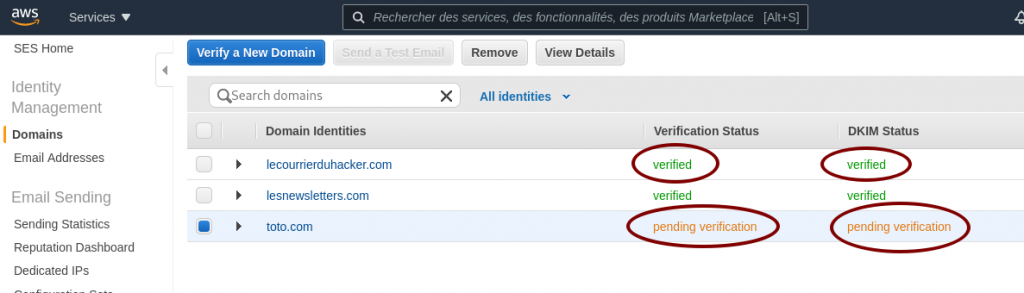 AWS SES pending verification
AWS SES pending verification AWS SES SMTP settings and credentials
AWS SES SMTP settings and credentials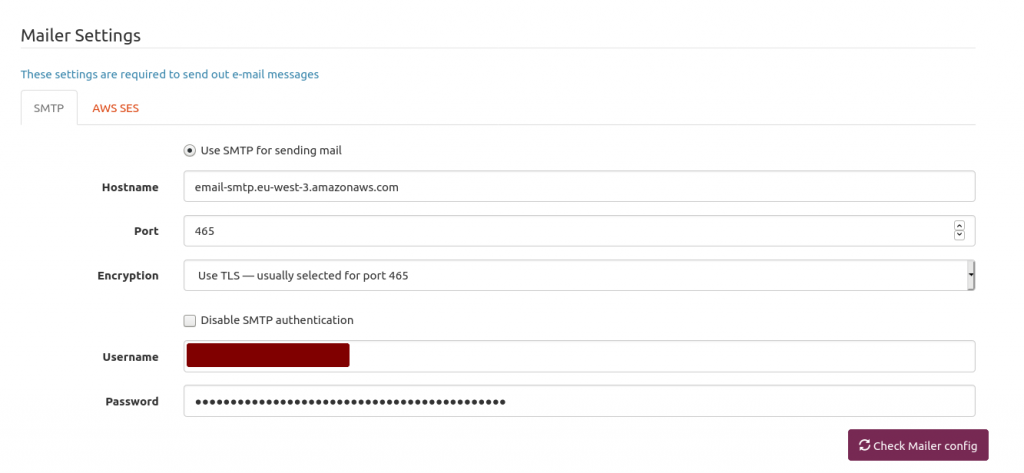 Mailtrain mailer setup
Mailtrain mailer setup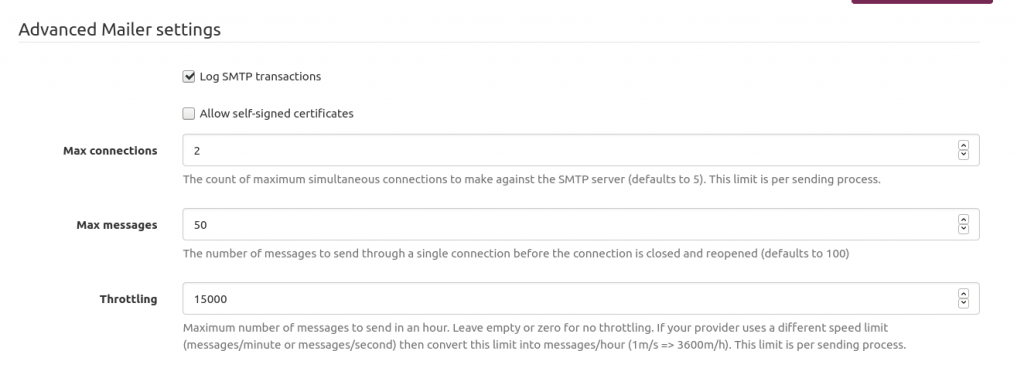 Mailtrain to throttle sending emails to AWS SES
Mailtrain to throttle sending emails to AWS SES